Table of Contents
Objective:
To understand the relationship between a prior, a likelihood, a posterior and the posterior predictive distribution. To understand that distributions can be placed over arbitrary objects, including things like abstract sequences of numbers.
Deliverable:
For this lab, you will turn in an ipython notebook that implements the “Bayesian Concept Learning” model from Chapter 3 of MLAPP.
Here is a PDF of the relevant chapter.
Your notebook should perform the following functions:
- Prompt the user for a set of numbers. (What happens if they only enter one number?)
- Display the prior, likelihood, and posterior for each concept
- Print the most likely concept
- Print the posterior predictive distribution over numbers
When you display your prior, likelihood, and posterior, your figure should look something like the ones in the book; my version is shown here:
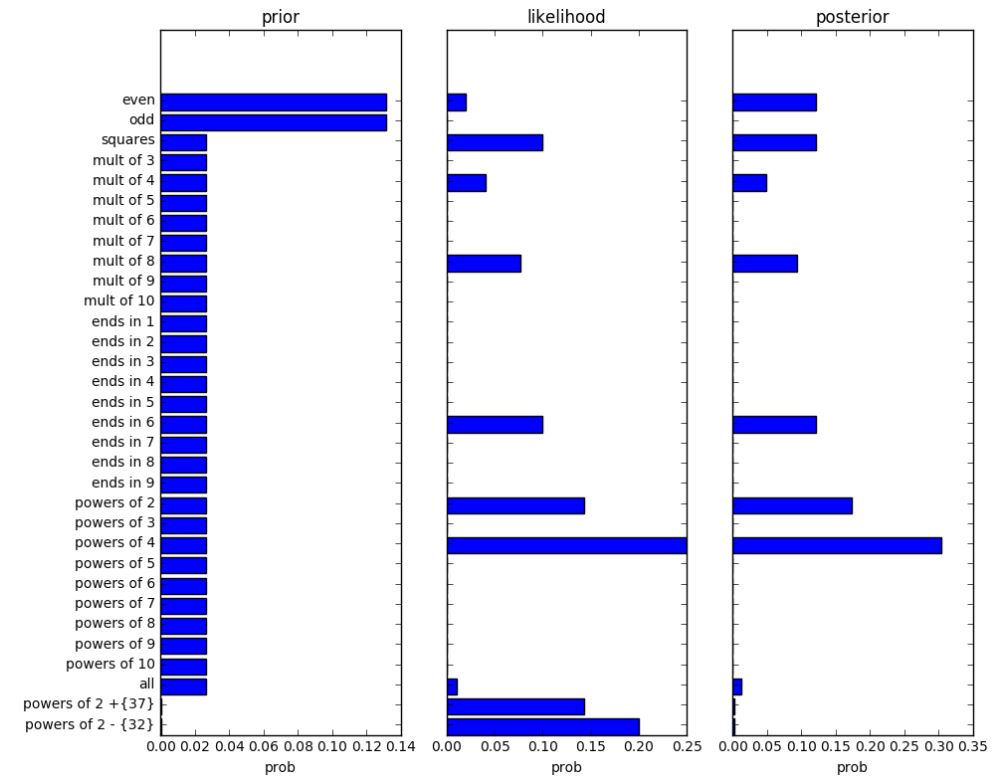
Similarly, when you display the posterior predictive, your figure should look something like this:

Grading standards:
Your notebook will be graded on the following:
- 10% Correctly formed & normalized prior
- 20% Correctly formed likelihood
- 30% Correctly formed & normalized posterior
- 30% Correctly formed & normalized posterior predictive
- 10% tidy and legible figures, including labeled axes
Remember: correct normalization may mean different things for different distributions!
Description:
Following the Bayesian Concept Learning example in Chapter 3 of MLAPP, we're interested in reasoning about the origin of a set of numbers. We'll do this by placing a prior over a set of possible concepts (or “candidate origins”), and then use Bayes' law to construct a posterior distribution over concepts given some data.
For this lab, we will only consider numbers between 0 and 100, inclusive.
Your notebook should construct a set of possible number-game concepts (such as “even” or “odd”). These can be any set of concepts you want, but should include at least all of the concepts in the book (see, for example, Fig. 3.2). You must assign a prior probability to each concept; the prior can be anything you want.
To make grading easier on our incredible TA, your notebook should construct a set of possible number-game concepts that are the same as the concepts in the book (see Fig. 3.2). You must assign a prior probability to each concept; to make grading easier, your prior should be:
prior = numpy.ones(len(concepts)) prior[0] = 5 prior[1] = 5 prior[30] = .01 prior[31] = .01 prior = prior / numpy.sum(prior)
This prior distribution is
$$p(h)$$
You must then prompt the user for some data. This will just be a sequence of numbers, like 16, 2,4,6 or 4,9,25. This is $\mathrm{data}$. You must then compute the likelihood of the $\mathrm{data}$, given the hypothesis:
$$p(\mathrm{data} | h )$$
Important: you can assume that each number in the data was sampled independently, and that each number was sampled uniformly from the set of all possible numbers in that concept.
Hint: what does that imply about the probability of sampling a given number from a concept with lots of possibilities, such as the all concept, vs. a concept with few possibilities, such as multiples of 10?
Prepare a figure, as described in the Deliverable that illustrates your prior, the likelihood of the data for each concept, the posterior. Note: distributions should be properly normalized.
You must also prepare a figure showing the posterior predictive distribution. This distribution describes the probability that a number $\tilde{x}$ is in the target concept (which we'll call $\mathrm{C}$), given the data. (Note that we're drawing a subtle distinction between the true concept and a hypothesis). The book is somewhat unclear on this, but to do this, we marginalize out the specific hypothesis:
$$p(\tilde{x} \in C | \mathrm{data} ) = \sum_h p(\tilde{x} \in C , h | \mathrm{data} )$$
$$p(\tilde{x} \in C | \mathrm{data} ) = \sum_h p(\tilde{x} \in C | h) p( h | \mathrm{data} )$$
We've already computed the posterior $p( h | \mathrm{data} )$, so we're only left with the term $p(\tilde{x} \in C | h)$. For this, just use an indicator function that returns 1 if $\tilde{x}$ is in $h$, and 0 otherwise.
Hint: just like any other distribution, the posterior predictive is normalized - but it is not normalized as a function of $\tilde{x}$. So what is it normalized over?
Hints:
You may find the following functions useful:
input('Please enter a set of numbers: ') len range filter map all import matplotlib.pyplot as plt import seaborn plt.figure( 42 ) plt.clf() plt.subplot plt.barh plt.title plt.xlabel # changes the xlimits of an axis plt.xlim # changes the ylimits of an axis plt.ylim
