Table of Contents
Objective:
To understand how to sample from different distributions, and to understand the link between samples and a PDF/PMF. To explore different parameter settings of common distributions, and to implement a small library of random variable types.
Deliverable:
You should turn in an ipython notebook that implements and tests a library of random variable types.
When run, this notebook should sample multiple times from each type of random variable; these samples should be aggregated and visualized, and compared to the corresponding PDF/PMF. The result should look something like this:
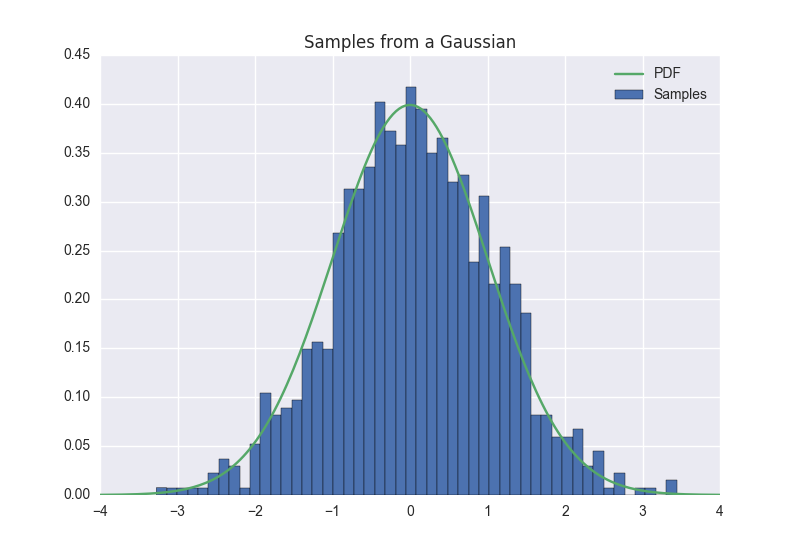
For multidimensional variables, your visualization should convey information in a natural way; you can either use 3d surfaces, or 2d contour plots:

Description:
You must implement seven random variable objects. For each type, you should be able to sample from that distribution, and compute the log-likelihood of a particular value. All of your classes should inherit from a base random variable object that supports the following methods:
class RandomVariable: def __init__( self ): self.state = None pass def get( self ): return self.state def sample( self ): pass def log_likelihood( self ): pass def propose( self ): pass
You don't need to implement the get or propose methods yet. For example, your univariate Gaussian class might look like this:
class Gaussian( RandomVariable ): def __init__( self, mu, sigma ): self.mu = mu self.sigma = sigma self.state = 0 def sample( self ): return self.mu + self.sigma * numpy.Random.randn() def log_likelihood( self, X, mu, sigma ): return -numpy.log( sigma*numpy.sqrt(2*pi) ) - (X-mu)**2/(sigma**2)
Given that framework, you should implement:
* The following one dimensional, continuous valued distributions. To visualize these, you should plot a histogram of sampled values, and also plot the PDF of the random variable on the same axis; they should (roughly) match. Note: it is not sufficient to let seaborn estimate the PDF using its built-in KDE estimator; you need to plot the true PDF. In other words, you can't just use seaborn.kdeplot!
Beta (a=1, b=3)Poisson (lambda=7)Univariate Gaussian (mean=2, variance=3)
* The following discrete distributions. For these, plot predicted and empirical histograms side-by-side:
Bernoulli (p=0.7)(hint: you may need a uniform random number)Multinomial (pvals=[0.1, 0.2, 0.7])
* The following multidimensional distributions. For these, use a contour or surface plot to visualize the empirical distribution of samples vs. the PDF:
Multivariate Gaussian ( mean=[2.0,3.0], cov=1.0,0.9],[0.9,1.0 )Dirichlet ( alpha=[ 0.1, 0.2, 0.7 ] )
Important notes:
You may use numpy.random to sample from the appropriate distributions.
You may not use any existing code to calculate the log-likelihoods. But you can, of course, use any online resources or the book to find the appropriate definition of each PDF.
Hints:
The following functions may be useful to you:
numpy.random matplotlib.pyplot.contour seaborn.kdeplot seaborn.jointplot hist( data, bins=50, normed=True ) numpy.linspace legend title
