Table of Contents
Objective:
To understand expectation maximization, and to explore how to learn the parameters of a Gaussian mixture model.
Deliverable:
For this lab, you will implement the Expectation Maximization algorithm on the Old Faithful dataset. This involves learning the parameters of a Gaussian mixture model. Your notebook should produce a visualization of the progress of the algorithm. The final figure could look something like this (they don't have to be arranged in subplots):
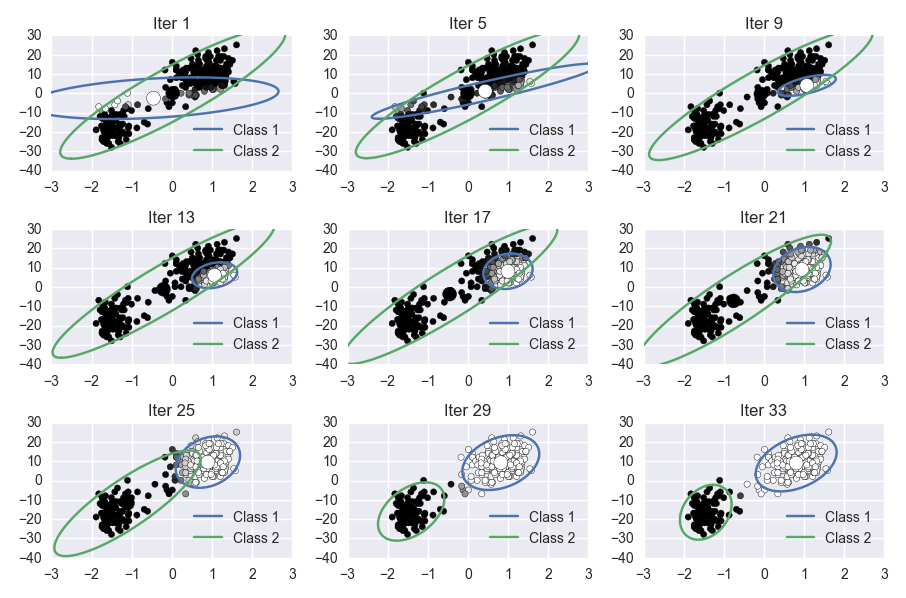
Grading:
Your notebook will be graded on the following elements:
- 10% Data is correctly mean-centered
- 20% Correctly updates responsibilities
- 20% Correctly updates means
- 20% Correctly updates covariances
- 20% Correctly updates mixing weights
- 10% Final plot(s) is tidy and legible
Description:
For this lab, we will be using the Expectation Maximization (EM) method to learn the parameters of a Gaussian mixture model. These parameters will reflect cluster structure in the data – in other words, we will learn probabilistic descriptions of clusters in the data.
For this lab, you will use the Old Faithful dataset, which you can download here:
The first thing you should is mean-center your data (ie, compute the mean of the data, then subtract that off from each datapoint). (If you don't do this, you'll get zero probabilities for all of your responsibilities, given the initial conditions discussed below.)
The equations for implementing the EM algorithm are given in MLAPP 11.4.2.2 - 11.4.2.3.
The algorithm is:
- Compute the responsibilities $r_{ik}$ (Eq. 11.27)
- Update the mixing weights $\pi_k$ (Eq. 11.28)
- Update the covariances $\Sigma_k$ (Eq. 11.32)
- Update the means $\mu_k$ (Eq. 11.31)
Now, repeat until convergence. Note that if you change the order of operations, you may get slightly difference convergences than the reference image.
Since the EM algorithm is deterministic, and since precise initial conditions for your algorithm are given below, the progress of your algorithm should closely match the reference image shown above.
For your visualization, please print out at least nine plots. These should color each datapoint using $r_{ik}$, and they should plot the means and covariances of the Gaussians. See the hints section for how to plot an ellipse representing the 95% confidence interval of a Gaussian, given an arbitrary covariance matrix.
Note: To help our TA better grade your notebook, you should use the following initial parameters:
# the Gaussian means (as column vectors -- ie, the mean for Gaussian 0 is mus[:,0] mus = np.asarray( [[-1.17288986, -0.11642103], [-0.16526981, 0.70142713]]) # the Gaussian covariance matrices covs = list() covs.append( np.asarray([[ 0.74072815, 0.09252716], [ 0.09252716, 0.5966275 ]]) ) covs.append( np.asarray([[ 0.39312776, -0.46488887], [-0.46488887, 1.64990767]]) ) # The Gaussian mixing weights mws = [ 0.68618439, 0.31381561 ] # called alpha in the slides
Hints:
In order to visualize a covariance matrix, you should plot an ellipse representing the 95% confidence bounds of the corresponding Gaussian. Here is some code that accepts as input a covariance matrix, and returns a set of points that define the correct ellipse; these points can be passed directly to the plt.plot() command as the x and y parameters.
import numpy as np def cov_to_pts( cov ): circ = np.linspace( 0, 2*np.pi, 100 ) sf = np.asarray( [ np.cos( circ ), np.sin( circ ) ] ) [u,s,v] = np.linalg.svd( cov ) pmat = u*2.447*np.sqrt(s) # 95% confidence return np.dot( pmat, sf )
Here are some additional python functions that may be helpful to you:
# compute the likelihood of a multivariate Gaussian scipy.stats.multivariate_normal.pdf # scatters a set of points; check out the "c" keyword argument to change color, and the "s" arg to change the size plt.scatter plt.xlim # sets the range of values for the x axis plt.ylim # sets the range of values for the y axis # to check the shape of a vector, use the .shape member foo = np.random.randn( 100, 200 ) foo.shape # an array with values (100,200) # to transpose a vector, you can use the .T operator foo = np.atleast_2d( [42, 43] ) # this is a row vector foo.T # this is a column vector import numpy as np np.atleast_2d np.sum
